Governing Automated Strategic Intelligence
Frontier AI systems can now fuse satellite imagery, shipping records, social-media traces, and corporate filings into analyst-grade answers in minutes. This paper asks who that shifts power toward and what governance should do before the answer becomes obvious.
What automated intelligence is
Intelligence analysis has traditionally required human teams that spend weeks manually collecting reports, imagery, signals, and financial records, then reconcile contradictions across those sources before producing a finished assessment. The paper's central claim is that frontier multimodal AI systems can now automate a significant part of this process — not by replacing the analyst's judgment, but by compressing the collection and synthesis phases from weeks to minutes.
The paper defines automated strategic intelligence as a system capable of ingesting heterogeneous open-source streams, representing their contents in a machine-queryable form, retrieving relevant evidence in response to a strategic question, reasoning over that evidence with a language model, and delivering a structured assessment to a decision-maker with provenance attached.
The five-stage pipeline
1. Ingestion. Gather and deduplicate imagery, tabular records, documents, broadcasts, and API feeds. The bottleneck here is usually data access and cleaning, not model capability.
2. Representation. Convert ingested material into forms a retrieval system can search — dense embeddings for semantic similarity, structured summaries for tabular reasoning, or OCR outputs for documents.
3. Retrieval. A reasoning agent issues tool calls that translate a strategic question into concrete database queries, returning the most relevant evidence chunks.
4. Reasoning. A frontier model analyses the retrieved material, calls more tools if needed, resolves conflicts between sources, and produces an answer with an attached confidence estimate.
5. Integration. The output is delivered to decision-makers with full provenance — which sources, which queries, which model version — and logged for future human or AI review.
A concrete example
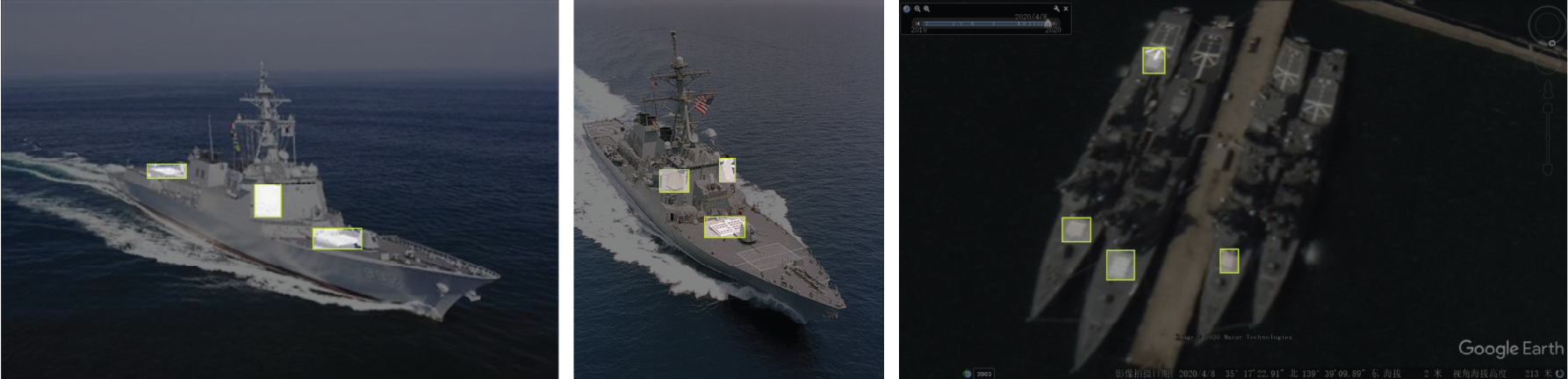
To make this tangible, consider one of the actual tasks used in the study: estimating what percentage of Starlink terminals shipped to Ukraine showed active signals near the frontline during a specified period.
Without AI assistance, a novice analyst would need to locate and cross-reference AIS shipping data, import records, geolocation feeds, and open-source reporting — a multi-day research effort with many opportunities for error.
With an automated intelligence stack, the ingestion stage pulls the relevant data streams; the representation stage converts terminal IDs to geolocated events; the retrieval stage surfaces the frontline-proximate signals; and the reasoning stage reconciles conflicting timestamps to produce a percentage estimate with source citations attached.
The study asks whether novices with access to a public LLM as a partial substitute for that stack can produce answers that look more like what a skilled analyst would write.
Exploratory uplift study
The empirical component is an exploratory study rather than a definitive experiment. The paper is transparent about this — the goal is to produce enough signal to motivate the governance argument, not to settle the empirical question.
Study design
Twenty novice participants and two skilled intelligence analysts worked on twelve intelligence-analysis tasks. Each task had a three-hour time limit. Novices were randomly assigned to either a control condition (no LLM) or a treatment condition (public LLM access permitted). Because most tasks lack clean public ground-truth answers, the outcome could not be a standard accuracy score.
The outcome measure
The paper defines an expert-similarity score: a normalised measure of how closely a participant's answer resembles the analyst-derived reference answer. If we denote the raw similarity for participant on task as , the score is normalised across tasks to have mean zero and unit variance:
This controls for task difficulty — a task where all participants score similarly contributes less variance to the estimate than one where scores spread widely. The normalised score is the dependent variable in all statistical models.
It is important to keep in mind what this measures. The study is not measuring whether LLM-assisted novices are correct in some objective sense. It is measuring whether they produce outputs that look more like what skilled analysts write. That is a meaningful proxy in a domain where ground truth is often unavailable, but it is not the same thing as accuracy.
Statistical model
The primary analysis uses a two-way fixed-effects model. Let indicate whether participant was in the treatment group. The model is:
where is a participant fixed effect absorbing individual baseline differences, is a task fixed effect absorbing differences in task difficulty, is the treatment effect of interest, and is the error term. The fixed effects are the key design choice: they let the model compare each participant to themselves across tasks rather than relying on between-participant variation, which is helpful given the small sample.
The estimate of interest is , interpreted as the average improvement in expert-similarity score (in standard-deviation units) attributable to LLM access, after removing participant and task baseline differences.
Results
The primary fixed-effects estimate is with and a one-sided . Two robustness checks are reported: a paired residual-difference test (, ) and a participant-stratified permutation test (, over 10,000 permutations).
Uplift estimates across specifications
| Analysis | Statistic | P-value | Interpretation | Effect () |
|---|---|---|---|---|
| Primary fixed-effects | 0.148 | t = 2.44 | p = 0.0355 | Positive and significant in the main specification. |
| Paired residual-difference | 0.153 | t = 2.796 | p = 0.025 | Same direction, also significant. |
| Participant-stratified permutation | 0.086 | 10,000 permutations | p = 0.219 | Positive but not conventionally significant. |
The permutation test not reaching conventional significance is the main reason the paper frames this as preliminary evidence. All three estimates point in the same direction. Two of three are conventionally significant. One is not. The honest conclusion is that the signal is consistent and positive but not yet conclusive. A larger, pre-registered study with more participants and a wider task set would be needed to settle it.
Even at face value, a standard-deviation shift in expert-similarity is strategically meaningful if it scales. If public models on consumer hardware can compress part of the novice-to-expert gap without any specialised infrastructure, then the barrier to entry for capable intelligence analysis is already lower than most governance frameworks assume.
Strategic implications
The paper argues the shift matters in at least three ways, each of which follows from the pipeline structure rather than from the uplift estimate alone.
Compression of the capacity gap. Intelligence analysis has historically required large, well-staffed bureaucracies with specialised training and classified access. If public models can automate the synthesis pipeline, smaller states and non-state actors can approach that capability with a fraction of the resources.
Asymmetric actor uplift. The bottleneck for many asymmetric actors is not data collection — open-source data is abundant — but synthesis: turning thousands of data points into a coherent strategic picture. Automated reasoning removes that bottleneck.
Shift in competitive advantage. If raw analyst headcount matters less, competitive advantage shifts toward access to proprietary data, frontier model quality, inference compute, and the scaffolding to integrate them. These are engineering and procurement problems, not recruitment ones.
Policy recommendations
The paper proposes five governance areas that follow from the pipeline analysis rather than from the uplift study alone. The argument is that even if the empirical results are weaker than presented, the pipeline architecture makes these recommendations prudent.
Five policy areas
| Area | Core aim |
|---|---|
| AI infrastructure protection | Protect compute, hardware, and frontier models; reduce strategic dependence on foreign AI infrastructure. |
| Data sovereignty and security | Keep critical datasets under domestic control and harden the systems that store and process them. |
| Open-source intelligence management | Treat public information as aggregatable intelligence and audit what an adversary could learn from it. |
| AI alignment and reliability | Invest in evaluation, interpretability, and human oversight before mission-critical deployment. |
| International cooperation | Build norms and agreements around responsible intelligence use before capability races become destabilizing. |
A sixth operational recommendation cuts across all five: continuous quantitative benchmarking. Any state or institution deploying AI for intelligence synthesis needs institutions that routinely measure accuracy, calibration, hallucination rates, and adversarial robustness — not just capability demos under favourable conditions.
Limitations
Sample size. Twenty novices and two analysts is a small study. The fixed-effects design extracts as much information as possible from that sample, but it cannot substitute for statistical power. The permutation test result — positive but not significant — is a direct reflection of this.
Outcome validity. Expert-similarity is a proxy for accuracy, not accuracy itself. Analysts can be wrong. If the study's analysts share systematic biases, the measure rewards replicating those biases rather than correct reasoning.
Task selection. The twelve tasks were chosen to represent intelligence-style questions, but they were not drawn from a formally defined universe. Generalisability to the full range of strategic intelligence problems is unknown.
Model version. The study used specific public LLMs at a point in time. The results say something about what models could do in mid-2025; they do not directly predict what more capable models will do in 2026 or 2027.
References
Nicholson, M. (2025). Governing Automated Strategic Intelligence. arXiv:2509.17087. arxiv.org/abs/2509.17087
Gupta, A. (2024). Open-source satellite imagery and object detection for naval vessel identification. Technical report.
Lowenthal, M. M. (2020). Intelligence: From Secrets to Policy (8th ed.). CQ Press.
Andregg, M. (2006). On the epistemology of intelligence. Intelligence and National Security, 21(2), 253–274.
Omand, D. (2010). Securing the State. Columbia University Press.
Clark, R. M. (2019). Intelligence Analysis: A Target-Centric Approach (6th ed.). CQ Press.